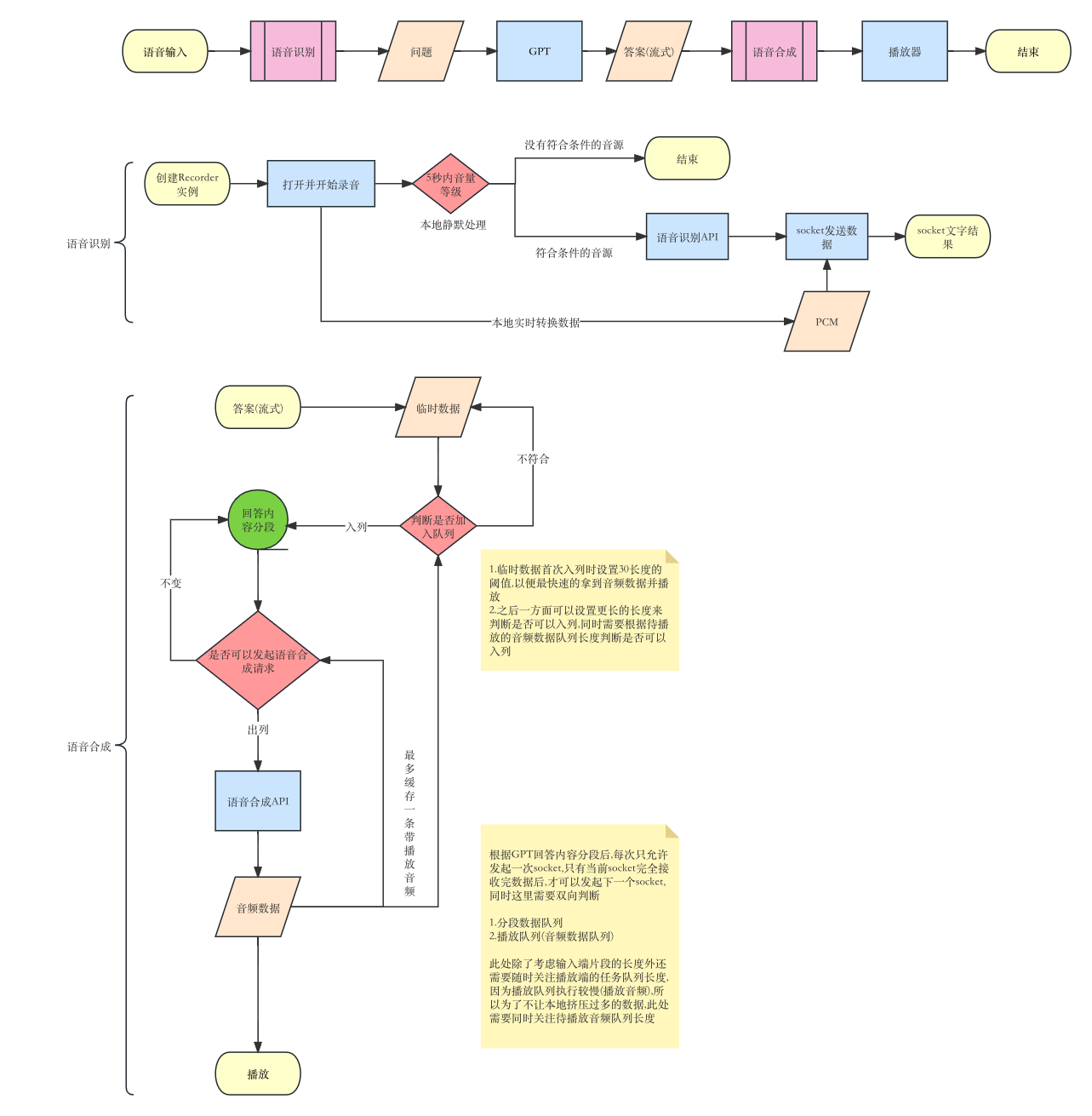
首先是下面的流程图,最终呈现的效果为,用户开启语音输入,识别问题后调用GPT获得结果的同时向讯飞发起语音合成.
___
1.语音识别
1.1 语音采集
语音识别目前由于浏览器的差异,目前有三种方式可用于进行语音采集
MediaRecorder:可以捕获浏览器中播放的音频或视频,并将其保存为文件或流媒体AudioWorklet:可以在独立的工作线程中编写和执行音频处理算法,而不会阻塞主线程的运行,同样这是一项实验功能,所以在一些老旧的浏览器并不支持.
ScriptProcessor:古董级的处理,目前来说所有的浏览器都支持,实际中发现华为的一系列手机支持情况不是很好
这里建议三种方式同时使用,这里有两个库可以参考:
如果是简单的功能不需要做兼容处理可以考虑这个库.核心代码很简单,可以根据自己的需求重写连接
对于复杂项目建议使用第三方库 链接
1.2 静默处理
本地语音采集开启后,再连接讯飞socket前,可以在本地添加静默时间,即用户在一定时间内没有声音输出时,即可终止所有操作
下面是rxjs的实现方式,可以参考
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| readonly startRecorder$ = new Subject<void>(); //开始连接语音
readonly powerLevel$ = new Subject<number>(); //音量等级,此处是粗略的计算
this.vadEosSubscription = this.powerLevel$
.pipe(
first((val) => val > 5),//截取音量大于5的值后完成源Observable
timeout(5000),//5S后查看当前最大音量等级值,若5s内没有符合条件的值则源Observable失败
repeatWhen(() => this.startRecorder$),每次连接语音时重启源Observable
catchError((e) => {
//timeout失败错误处理,表示用户5秒内没有符合要求的音量值
return throwError(() => new Error(e));
})
)
.subscribe((r) => {
//有符合要求的音量值可以连接讯飞socket
});
|
关于粗略的计算音频PCM信号的音量,可以采用采样点幅值的面积(能量)来计算,计算公式为:20*log10(x/y);此处不过多考虑,可以具体搜索PCM计算音量
1.3 本地数据处理
讯飞语音识别需要满足的数据格式如下:
- 未压缩的PCM格式,每次发送音频间隔40ms,每次发送音频字节数1280B;
- 讯飞定制speex格式,每次发送音频间隔40ms,假如16k的压缩等级为7,则每次发送61B的整数倍;
- 标准开源speex格式,每次发送音频间隔40ms,假如16k的压缩等级为7,则每次发送60B的整数倍;
1.3.1 原生方法开发
如果使用JS的原生方法开发,获取的数据为Float32格式,由于数据过于密集,这里就需要使用worker来对原始采集的数据进行转换,具体到不同的框架都有自己的worker实现,不过多说明.
具体的转换可以参考worker.ts代码,这里是将数据最后转成了PCM(16位小端LE)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
| //这里定义三个类型主要确定数据的开始和结束,讯飞的demo里也是类似的实现
export interface Worker {
type: 'init' | 'message' | 'stop';
data: {
frameSize: number;
sampleRate: number;
audioBuffers: Float32Array;
};
}
addEventListener('message', (event: MessageEvent<Worker>) => {
const { data } = event;
const { type } = data;
switch (type) {
case 'init':
transAudioData.init(data.data.frameSize, data.data.sampleRate);
break;
case 'message':
transAudioData.frameBuffer.push(
...transAudioData.transcode(data.data.audioBuffers)
);
//截取参数设置的帧数大小
if (
transAudioData.frameBuffer &&
transAudioData.frameBuffer.length >= transAudioData.frameSize
) {
postMessage({
frameBuffer: transAudioData.frameBuffer.splice(
0,
transAudioData.frameSize
),
isLastFrame: false,
});
}
break;
case 'stop':
postMessage({
frameBuffer: transAudioData.frameBuffer.splice(
0,
transAudioData.frameSize
),
isLastFrame: true,
});
transAudioData.frameBuffer = [];
break;
}
});
const transAudioData: {
inputSampleRate: number;
inputSampleBits: number;
frameSize: number;
frameBuffer: Array<Float32Array>;
init: (frameSize: number, sampleRate: number) => void;
transcode: (e: Float32Array) => Float32Array[];
to16kHz: (e: Float32Array) => Float32Array;
to16BitPCM: (e: Float32Array) => DataView;
} = {
inputSampleRate: 0, //采样率
inputSampleBits: 16, //采样位数
frameSize: 1280,
frameBuffer: [],
init(frameSize, sampleRate) {
this.inputSampleRate = sampleRate;
this.frameSize = frameSize;
},
transcode(audioData) {
let output: any = transAudioData.to16kHz(audioData);
output = transAudioData.to16BitPCM(output);
output = Array.from(new Uint8Array(output.buffer));
return output;
},
to16kHz(audioData) {
const data = new Float32Array(audioData);
const fitCount = Math.round(data.length * (this.inputSampleRate / 44100));
const newData = new Float32Array(fitCount);
const springFactor = (data.length - 1) / (fitCount - 1);
newData[0] = data[0];
for (let i = 1; i < fitCount - 1; i++) {
const tmp = i * springFactor;
const before = Number(Math.floor(tmp).toFixed());
const after = Number(Math.ceil(tmp).toFixed());
const atPoint = tmp - before;
newData[i] = data[before] + (data[after] - data[before]) * atPoint;
}
newData[fitCount - 1] = data[data.length - 1];
return newData;
},
to16BitPCM(input) {
const dataLength = input.length * (16 / 8);
const dataBuffer = new ArrayBuffer(dataLength);
const dataView = new DataView(dataBuffer);
let offset = 0;
for (let i = 0; i < input.length; i++, offset += 2) {
const s = Math.max(-1, Math.min(1, input[i]));
dataView.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7fff, true);
}
return dataView;
},
};
|
1.3.2 第三方库
一般第三方库有自己的数据处理逻辑,可以直接拿到符合要求的数据格式
1.4 数据提交
通过上述介绍,在实际的开发中音频采集的状态和音频数据会是两条完全异步的数据流,具体的实现有很多方法,这里我个人采用了Rxjs,定义两条数据流,同时定义数据类型
- 音频采集的开启和关闭(RecorderManagerObservable)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| /**
* 语音录制状态
*/
export interface RecorderManagerObservable {
status: RecorderManagerStatus;
}
export enum RecorderManagerStatus {
/**
* 未连接
*/
'unconnected' = 'unconnected',
/**
* 状态:连接
* 本地语音有初始静默处理,此时表示已经有有效数据.可以连接讯飞语音识别socket
*/
'open' = 'open',
/**
* 语音断开
*/
'close' = 'close',
}
|
- 音频数据的本地缓存(AudioDataByRecorderObservable)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| /**
* 语音数据(本地Recorder获取)
* IAT(音频转文字)使用
*/
export interface AudioDataByRecorderObservable<T extends RecorderMangerData> {
status: AudioDataByRecorderStatus;
data: T;
}
export enum AudioDataByRecorderStatus {
/**
* 数据帧记录
*/
'frameRecorded' = 'frameRecorded',
/**
* 结束
*/
'end' = 'end',
/**
* 错误
*/
'error' = 'error',
}
//数据类型
export type RecorderMangerData =
| RecorderMangerFrameRecordedData
| RecorderMangerStopData
| RecorderMangerErrorData;
//录制中
export type RecorderMangerFrameRecordedData = {
audioData: string;
isLastFrame: boolean;
};
//录制结束
export type RecorderMangerStopData = null;
//录制失败
export type RecorderMangerErrorData = string;
|
具体的流程如前面的图里所示:
开启录音(处理并缓存音频数据)=>静默处理=>终止/连接socket=>根据实际情况持续提交音频数据=>结束录音=>获得结果
1.5 结果
之后从讯飞socket中获取结果后即可向GPT发起问题,等待GPT的回答
1.6其他
关于开启和关闭录音,这里一般有两种交互模式,即用户点击开启/点击关闭和长按输入/松开结束,这里需要根据自己的实际环境决定采用哪种方式,由于在获取音频的时候,第一次浏览器会有弹框询问,所以可以考虑将获取音频和开启录制分开来实现,但是在某些H5环境下每次都会询问用户是否授权录音,所以这里需要着重考虑清楚
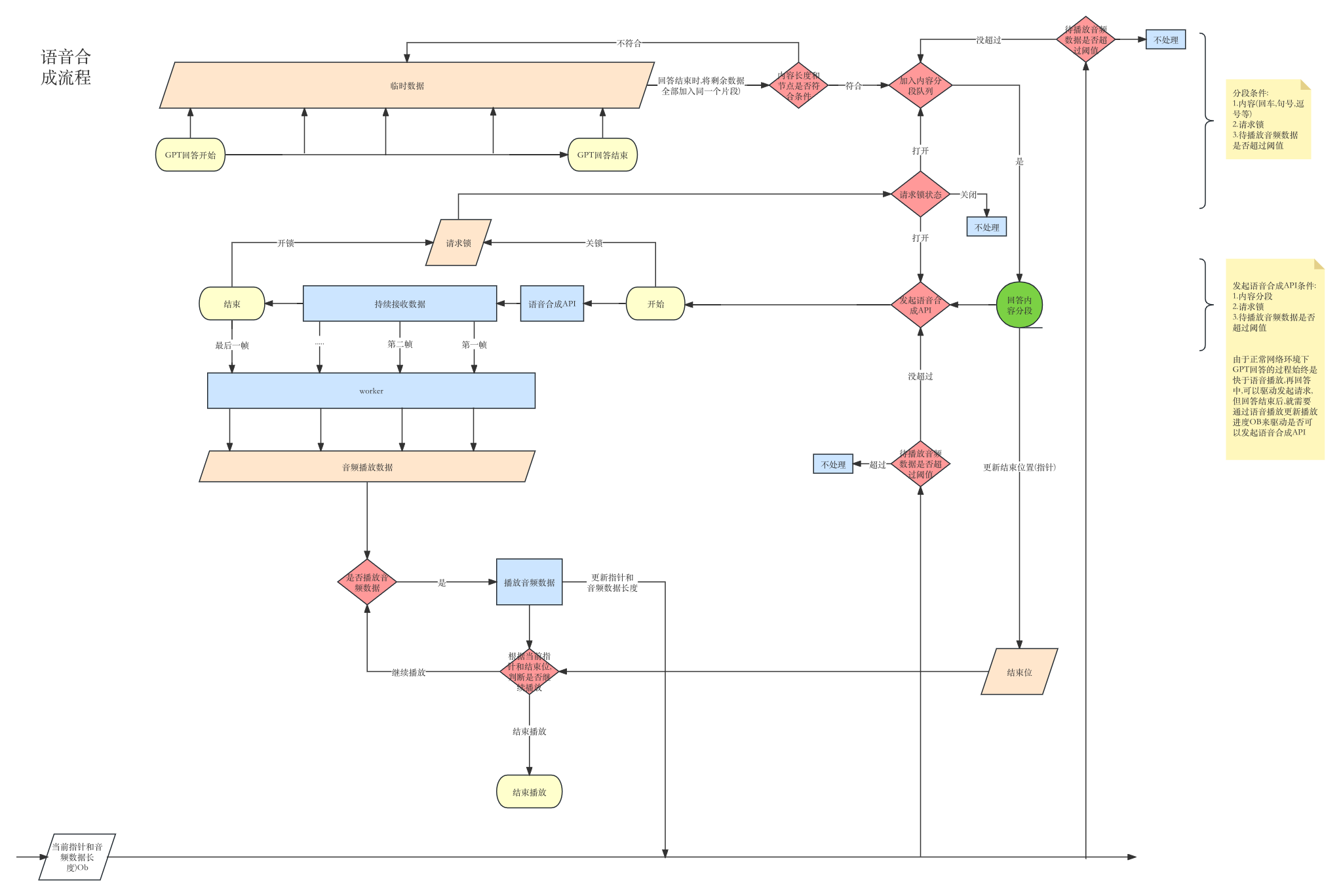
2.语音合成
由于讯飞的语音合成API为流式输出,但是只支持单次上传,而实际的需求是GPT回答的同时语音输出,所以在调用讯飞语音合成时,首先需要根据回答内容对其进行分段,然后顺序调用讯飞API拿取音频结果并播放,基于以上的流程图我们可以将整个过程分为三个部分的功能
- GPT数据的分段功能
- 请求和获取语音数据
- 播放语音数据
2.1 GPT回答分段
由于GPT的回答是流式输出,需要临时缓存每一次的回复数据,并分段.而分段时我们需要同时考虑以下几个条件:
- 当前内容是否处于分段节点(回车,逗号,句号,长度是否满足)
- 请求锁是否打开(是否有正在进行中的websocket(讯飞API))
- 播放音频的指针是否合适(本地没有积压过多的待播放音频数据)
第一个条件:为了满足每一段的语音节点都处于断句出,这样可以让语音的输出更有可读性.
第二个条件:因为语音的输出具有连贯性,只有前一段的语音数据全部接收完毕,下一段的语音数据才具有意义.所以需要保证前一段的语音数据接收完毕后才可以发起新的请求
第三个条件:由于API的整个过程在时间上是快于语音的播放,并且为了尽可能少的请求API(减少调用次数),所以本地的尽可能少的缓存语音数据,这里可以缓存一段待播放的音频数据即可,后续可以根据自己的需要调整阈值
注意:在这个过程中我们同时需要记录以下几个数据
- GPT回答分段指针:处理语音数据时,需要根据指针持续更新对应片段的语音数据
- 结束位:GPT回答分段是否已经结束,用于通知播放器是否可以停止播放音频数据
2.2 处理语音数据
在是否可以调用API时,我们需要满足以下几个条件
- 是否有分段内容
- 请求锁是否打开(保证每次只调用一个API)
- 待播放音频数据是否超过阈值(本地没有积压过多的待播放音频数据)
当上述三个条件都满足时,即可开始调用API;
同时针对单次的讯飞API请求,我们在获得数据的时候需要根据GPT回答内容的分段标记指针位置,在这个过程中更新对应指针的语音数据,需要额外注意的是,由于拿到的语音数据不能直接播放,需要经过worker计算才可,具体的代码由于原生和各个框架的处理情况不一样,可以根据自己的实际开发环境实现.
2.3 播放音频数据
从worker拿到音频数据并缓存后,根据回答分段时记录的结束位判断是否可以继续播放,开始播放时即可更新播放的指针位置和音频数据长度,同时通知GPT回答分段本地的待播放音频数据是否超过阈值.
以上即是语音合成的整个过程,这个过程代码过于分散,可以根据自己的实际开发环境按照上述的过程处理即可,额外需要注意的时,由于整个过程中存在大量的异步处理,这里个人采用rxjs的方式处理,对应的需要创建以下几个Ob,可以参考
- GPTSectionOb(GPT分段Observable)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| /**
* GPT回答内容分段
*/
export interface GPTSectionObservable {
status: GPTSectionStatus;
data?: AsAny.AsAny;
}
/**
* GPT回答状态
*/
export enum GPTSectionStatus {
'start' = 'start', //初始化
'doing' = 'doing', //GPT回答中
'end' = 'end', //回答结束
'cancel' = 'cancel', //取消
}
|
- TTS_PlayerStatusObservable(控制播放器Observable,可以不需要,这里因为项目内还需要处理VRM和其他的操作)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| export interface TTS_PlayerStatusObservable {
status: TTS_Status;
}
//音频转文字播放器状态
export enum TTS_Status {
/**
* 初始化
*/
'ready' = 'ready',
/**
* 开始播放
*/
'start' = 'start',
/**
* 播放中
*/
'playing' = 'playing',
/**
* 播放结束
*/
'end' = 'end',
/**
* 取消播放
*/
'cancel' = 'cancel',
}
|
- AudioDataPlayingQueueOb(记录播放指针和音频数据长度的Observable)
1
2
3
4
5
| export interface AudioDataPlayingQueueObservable {
data: Array<AsAny.AsAny>;//音频数据
index: number; //当前播放的指针
}
|